Diffusion Models for Adversarial Purification

Abstract
Adversarial purification refers to a class of defense methods that remove adversarial perturbations using a generative model. These methods do not make assumptions on the form of attack and the classification model, and thus can defend pre-existing classifiers against unseen threats. However, their performance currently falls behind adversarial training methods. In this work, we propose DiffPure that uses diffusion models for adversarial purification: Given an adversarial example, we first diffuse it with a small amount of noise following a forward diffusion process, and then recover the clean image through a reverse generative process. To evaluate our method against strong adaptive attacks in an efficient and scalable way, we propose to use the adjoint method to compute full gradients of the reverse generative process. Extensive experiments on three image datasets including CIFAR-10, ImageNet and CelebA-HQ with three classifier architectures including ResNet, WideResNet and ViT demonstrate that our method achieves the state-of-the-art results, outperforming current adversarial training and adversarial purification methods, often by a large margin.
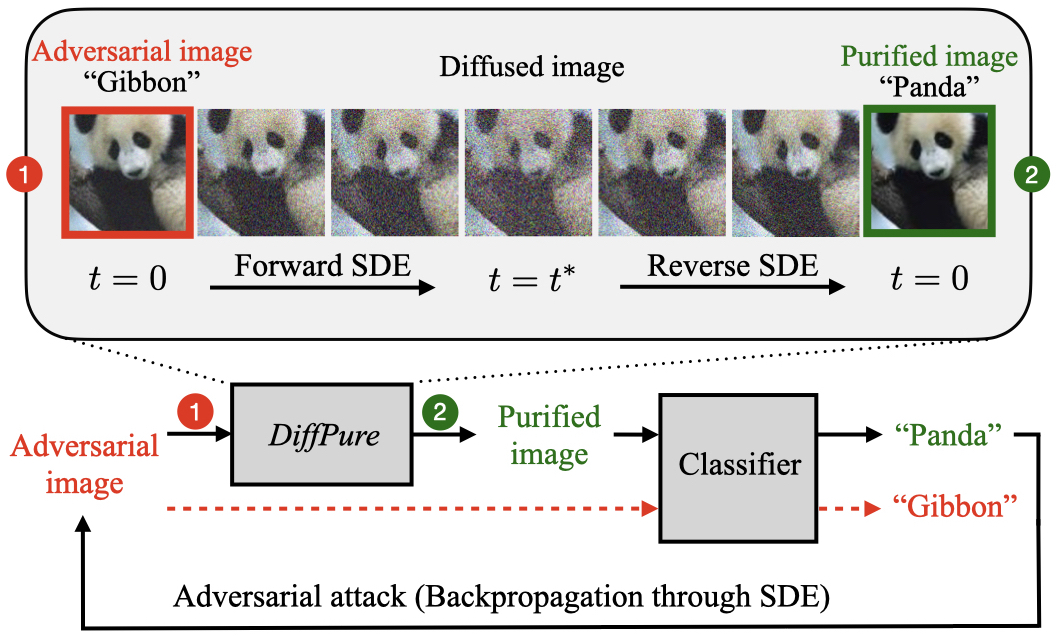
Adversarial Purification with Diffusion Models
We propose a new adversarial purification method, termed DiffPure, that uses the forward and reverse processes of diffusion models to purify adversarial images. Specifically, given a pre-trained diffusion model, our method consists of two steps: (i) we first add noise to adversarial examples by following the forward process with a small diffusion timestep, and (ii) we then solve the reverse stochastic differential equation (SDE) to recover clean images from the diffused adversarial examples. An important design parameter in our method is the choice of diffusion timestep, since it represents the amount of noise added during the forward process. Our theoretical analysis reveals that the noise needs to be high enough to remove adversarial perturbations but not too large to destroy the label semantics of purified images.
Furthermore, strong adaptive attacks require gradient backpropagation through the SDE solver in our method, which suffers from the memory issue if implemented naively. In particular, denoted by N the number of function evaluations in solving the SDE, the required memory increases by O(N). Thus, we propose to use the adjoint method to efficiently calculate full gradients of the reverse SDE with a constant memory cost.

The first column shows adversarial examples produced by attacking attribute classifiers using PGD 𝓁∞ (ε=16/255). Our method purifies the adversarial examples by first diffusing them up to the timestep t=0.3, following the forward diffusion process, and then, it removes perturbations using the reverse generative SDE. The middle three columns show the intermediate results of solving the reverse SDE in DiffPure at different timesteps. We observe that the purified images at t=0 match the clean images (last column).
Main Results
We empirically compare our method against the latest adversarial training and adversarial purification methods on various strong adaptive attack benchmarks. Extensive experiments on three datasets (i.e., CIFAR-10, ImageNet and CelebA-HQ) across multiple classifier architectures (i.e., ResNet, WideResNet and ViT) demonstrate the state-of-the-art performance of our method.
- Comparison with adversarial training. Compared to the state-of-the-art adversarial training methods against AutoAttack 𝓁∞ , our method shows absolute improvements of up to +7.68% on ImageNet in robust accuracy.
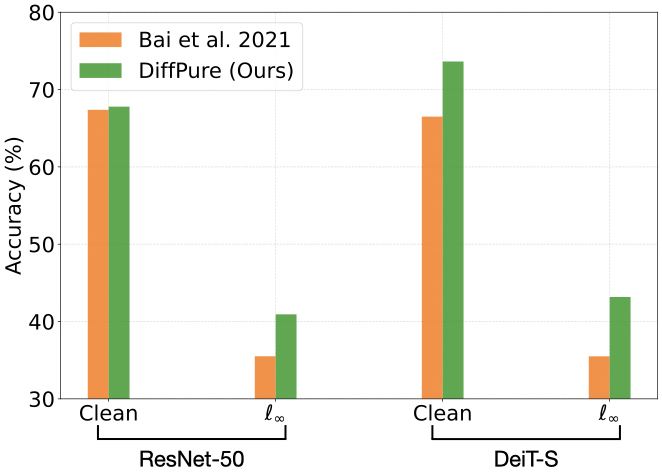
Comparison with state-of-the-art adversarial training methods against AutoAttack on ImageNet with ResNet-50 and DeiT-S, respectively.
- Comparison with other purification methods. In comparison to the state-of-the-art adversarial purification methods against the BPDA+EOT attack, we have absolute improvements of +11.31% on CIFAR-10 in robust accuracy.
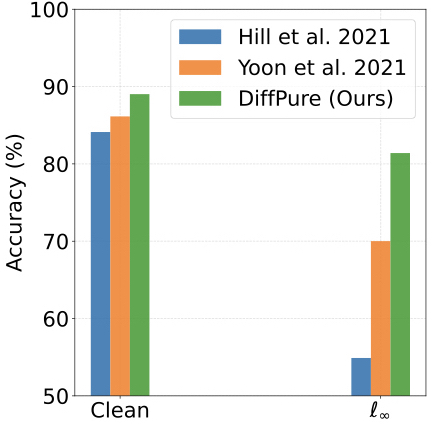
Comparison with latest purification methods against the adaptive black-box BPDA+EOT attack on WideResNet-28-10 for CIFAR-10.
- Defense against unseen threats. Compared to the latest adversarial training methods against unseen threats, our method exhibits a more significant absolute improvement (up to +36% in robust accuracy).
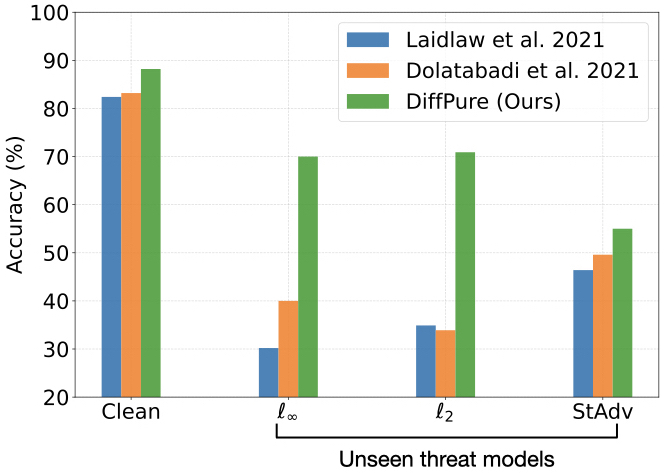
Comparison with state-of-the-art defense methods against unseen threat models (including AutoAttack 𝓁∞, AutoAttack 𝓁2, and StdAdv) on ResNet-50 for CIFAR-10.
Our Insights and Limitations
DiffPure uses different noise levels in the diffusion process of a diffusion model to smooth out perturbations and then recovers clean images in the denoising process. It can maintain the class semantics during purification due to the generative power of diffusion models. It also introduces proper noise injection in the forward and reverse processes for a stronger defense. These factors make DiffPure better than previous methods. Thus, we think DiffPure is more transparent than adversarial training that instead heavily relies on specialized training strategies.
Our method has two major limitations: (i) the purification process takes much time (proportional to the diffusion timestep), making our method inapplicable to the real-time tasks, and (ii) diffusion models are sensitive to image colors, making our method incapable of defending color-related corruptions. It is interesting to either apply recent works on accelerating diffusion models or design new diffusion models specifically for model robustness to overcome these two limitations.
Paper

Diffusion Models for Adversarial Purification
Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, Anima Anandkumar
Citation
@inproceedings{nie2022DiffPure,
title={Diffusion Models for Adversarial Purification},
author={Nie, Weili and Guo, Brandon and Huang, Yujia and Xiao, Chaowei and Vahdat, Arash and Anandkumar, Anima},
booktitle = {International Conference on Machine Learning (ICML)},
year={2022}
}